
 文档
文档
Plumelog使用方法 #
- 使用前请耐心的按照步骤把文档看完,需要对logback,log4j两大日志框架基本配置有一定了解
使用前注意事项 #
-
plumelog分三种启动模式,分别为redis,kafka,lite,外加嵌入式版本plumelog-lite,大家根据自己的需求使用部署
-
lite模式也就是单机版,不依赖任何外部中间件直接启动使用,部署极其方便,但是性能有限,一天10个G以内可以应付,最好是SSD硬盘,适合管理系统类的小玩家,一个公司有很多小系统需要日志集中管理
-
redis,kafka模式可以集群分布式部署,适合大型玩家,互联网公司,具体是用redis还是kafka,看每个公司运维情况
-
plumelog-lite plumelog的嵌入式集成版本,直接pom引用,嵌入在项目中,自带查询界面,适合单个独立小项目使用,外包软件的最佳伴侣
一、服务端安装配置 #
(1)服务端安装 #
第一步:安装 redis 或者 kafka(一般公司redis足够) redis 官网:https://redis.io kafka:http://kafka.apache.org
第二步:安装 elasticsearch 官网下载地址:https://www.elastic.co/cn/downloads/past-releases
第三步:下载安装包,plumelog-server 下载地址:https://gitee.com/plumeorg/plumelog/releases
第四步:配置plumelog-server,并启动,redis和kafka作为队列模式下可以部署多个plumelog-server达到高可用,配置一样即可
第五步:后台查询语法详见plumelog使用指南
(2)服务端配置 #
- 文件 plumelog-server/application.properties 详解:
#值为4种 redis,kafka,rest,restServer,lite
#redis 表示用redis当队列
#kafka 表示用kafka当队列
#rest 表示从rest接口取日志
#restServer 表示作为rest接口服务器启动
#ui 表示单独作为ui启动
#lite 简易模式启动不需要配置redis,es等
plumelog.model=redis
#lite模式下日志存储路径
#plumelog.lite.log.path=/lucene
#如果使用kafka,启用下面配置
#plumelog.kafka.kafkaHosts=172.16.247.143:9092,172.16.247.60:9092,172.16.247.64:9092
#plumelog.kafka.kafkaGroupName=logConsumer
#队列redis地址,model配置redis集群模式,哨兵模式用逗号隔开,队列redis不支持集群模式,lite模式可以全部注释掉下面配置
#当redis队列性能不够的时候,可以不同的项目单独配置单独的redis队列,用单独的plumelog-server去采集,公用一个管理redis
plumelog.queue.redis.redisHost=127.0.0.1:6379
#如果使用redis有密码,启用下面配置
#plumelog.queue.redis.redisPassWord=123456
#如果要切换db,redis必须要配置密码
#plumelog.queue.redis.redisDb=0
#哨兵模式需要配置的
#plumelog.queue.redis.sentinel.masterName=myMaster
#redis解压缩模式,开启后不消费非压缩的队列
#plumelog.redis.compressor=true
#管理端redis地址 ,集群用逗号隔开,不配置将和队列公用,lite模式可以全部注释掉下面配置,管理redis单独使用的时候支持集群模式
#plumelog.redis.redisHost=127.0.0.1:6379
#如果使用redis有密码,启用下面配置
#plumelog.redis.redisPassWord=123456
#plumelog.redis.redisDb=0
#哨兵模式需要配置的
#plumelog.redis.sentinel.masterName=myMaster
#如果使用rest,启用下面配置
#plumelog.rest.restUrl=http://127.0.0.1:8891/getlog
#plumelog.rest.restUserName=plumelog
#plumelog.rest.restPassWord=123456
#elasticsearch相关配置,Hosts支持携带协议,如:http、https,集群逗号隔开,lite模式可以全部注释掉下面配置
plumelog.es.esHosts=127.0.0.1:9200
plumelog.es.shards=5
plumelog.es.replicas=1
plumelog.es.refresh.interval=30s
#日志索引建立方式day表示按天、hour表示按照小时
plumelog.es.indexType.model=day
#hour模式下需要配置这个
#plumelog.es.maxShards=100000
#ES设置密码,启用下面配置
#plumelog.es.userName=elastic
#plumelog.es.passWord=elastic
#是否信任自签证书
#plumelog.es.trustSelfSigned=true
#是否hostname验证
#plumelog.es.hostnameVerification=false
#以下配置不管什么模式都要配置
#单次拉取日志条数
plumelog.maxSendSize=100
#拉取时间间隔,kafka不生效
plumelog.interval=100
#plumelog-ui的地址 如果不配置,报警信息里不可以点连接
plumelog.ui.url=http://demo.plumelog.com
#管理密码,手动删除日志的时候需要输入的密码
admin.password=123456
#日志保留天数,配置0或者不配置默认永久保留
admin.log.keepDays=30
#链路保留天数,配置0或者不配置默认永久保留
admin.log.trace.keepDays=30
#登录配置,配置后会有登录界面
#login.username=admin
#login.password=admin
(3)提升性能推荐参考配置方法 #
-
单日日志体量在50G以内,并使用的SSD硬盘
plumelog.es.shards=5
plumelog.es.replicas=0
plumelog.es.refresh.interval=30s
plumelog.es.indexType.model=day
-
单日日志体量在50G以上,并使用的机械硬盘
plumelog.es.shards=5
plumelog.es.replicas=0
plumelog.es.refresh.interval=30s
plumelog.es.indexType.model=hour
-
单日日志体量在100G以上,并使用的机械硬盘
plumelog.es.shards=10
plumelog.es.replicas=0
plumelog.es.refresh.interval=30s
plumelog.es.indexType.model=hour
-
单日日志体量在1000G以上,并使用的SSD硬盘,这个配置可以跑到10T一天以上都没问题
plumelog.es.shards=10
plumelog.es.replicas=1
plumelog.es.refresh.interval=30s
plumelog.es.indexType.model=hour
-
plumelog.es.shards的增加和hour模式下需要调整ES集群的最大分片数
PUT /_cluster/settings
{
"persistent": {
"cluster": {
"max_shards_per_node":100000
}
}
}
二、客户端使用 #
(1)注意事项 #
-
1.客户端在项目使用,非maven项目下载依赖包( https://gitee.com/frankchenlong/plumelog/releases )放在自己的lib下面直接使用,去除重复的包即可使用,然后配置log4j就可以搜集日志了
-
2.推荐使用logback,特别是springboot,springcloud项目;注意:3.2版本logback有bug,请使用3.2.1修复版本或者以上版本
-
3.示例中仅仅是基本配置,更多配置请看文章下面配置详解
-
4.示例中plumelog相关版本号为示例,实际使用建议取最新的版本,最新的版如下
(2)客户端配置 #
1.log4j #
- 引入
<dependency>
<groupId>com.plumelog</groupId>
<artifactId>plumelog-log4j</artifactId>
<version>3.5.2</version>
</dependency>
- 配置log4j配置文件,增加下面这个Appender,示例如下:
#三选一加入到root
log4j.rootLogger=INFO,stdout,L
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=[%-5p] %d{yyyy-MM-dd HH:mm:ss,SSS} [%c.%t]%n%m%n
#kafka做为中间件
log4j.appender.L=com.plumelog.log4j.appender.KafkaAppender
#appName系统的名称(自己定义就好)
log4j.appender.L.appName=plumelog
log4j.appender.L.env=${spring.profiles.active}
log4j.appender.L.kafkaHosts=172.16.247.143:9092,172.16.247.60:9092,172.16.247.64:9092
#redis做为中间件
log4j.appender.L=com.plumelog.log4j.appender.RedisAppender
log4j.appender.L.appName=plumelog
log4j.appender.L.env=${spring.profiles.active}
log4j.appender.L.redisHost=172.16.249.72:6379
#redis没有密码这一项为空或者不需要
#log4j.appender.L.redisAuth=123456
#lite模式
log4j.appender.L=com.plumelog.log4j.appender.LiteAppender
log4j.appender.L.appName=plumelog
log4j.appender.L.env=${spring.profiles.active}
log4j.appender.L.plumelogHost=localhost:8891
同理如果使用logback,和log4j2配置如下,示例如下:
2.logback #
- 引入
<dependency>
<groupId>com.plumelog</groupId>
<artifactId>plumelog-logback</artifactId>
<version>3.5.2</version>
</dependency>
- 配置
<appenders>
<!--使用redis启用下面配置-->
<appender name="plumelog" class="com.plumelog.logback.appender.RedisAppender">
<appName>plumelog</appName>
<redisHost>172.16.249.72:6379</redisHost>
<redisAuth>123456</redisAuth>
</appender>
<!-- 使用kafka启用下面配置 -->
<appender name="plumelog" class="com.plumelog.logback.appender.KafkaAppender">
<appName>plumelog</appName>
<kafkaHosts>172.16.247.143:9092,172.16.247.60:9092,172.16.247.64:9092</kafkaHosts>
</appender>
<!-- 使用lite模式启用下面配置 -->
<appender name="plumelog" class="com.plumelog.logback.appender.LiteAppender">
<appName>worker</appName>
<plumelogHost>localhost:8891</plumelogHost>
</appender>
</appenders>
<!--使用上面三个三选一加入到root下面-->
<root level="INFO">
<appender-ref ref="plumelog"/>
</root>
3.logback整合配置中心案例,推荐使用,不知道怎么配置的拷贝全部 #
- application.properties中添加
plumelog.appName=plumelog_demo
plumelog.redisHost=127.0.0.1:6379
plumelog.redisAuth=plumelogredis
spring.profiles.active=dev
- logback-spring.xml 不知道怎么配置的拷贝全部
<?xml version="1.0" encoding="UTF-8"?>
<configuration debug="false">
<conversionRule conversionWord="clr" converterClass="org.springframework.boot.logging.logback.ColorConverter"/>
<conversionRule conversionWord="wex"
converterClass="org.springframework.boot.logging.logback.WhitespaceThrowableProxyConverter"/>
<conversionRule conversionWord="wEx"
converterClass="org.springframework.boot.logging.logback.ExtendedWhitespaceThrowableProxyConverter"/>
<!-- 彩色日志格式 -->
<property name="CONSOLE_LOG_PATTERN"
value="${CONSOLE_LOG_PATTERN:-%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}}"/>
<!--输出到控制台-->
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<!--过滤trace日志到控制台-->
<filter class="com.plumelog.logback.util.FilterSyncLogger">
<level></level>
</filter>
<encoder>
<Pattern>${CONSOLE_LOG_PATTERN}</Pattern>
<!-- 设置字符集 -->
<charset>UTF-8</charset>
</encoder>
</appender>
<!-- 输出到文件 -->
<appender name="file" class="ch.qos.logback.core.rolling.RollingFileAppender">
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<FileNamePattern>logs/plumelog-demo.log.%d{yyyy-MM-dd}.log</FileNamePattern>
<MaxHistory>3</MaxHistory>
</rollingPolicy>
<encoder>
<Pattern>${CONSOLE_LOG_PATTERN}</Pattern>
<!-- 设置字符集 -->
<charset>UTF-8</charset>
</encoder>
</appender>
<!-- 环境配置 -->
<springProperty scope="context" name="plumelog.appName" source="plumelog.appName"/>
<springProperty scope="context" name="plumelog.redisHost" source="plumelog.redisHost"/>
<springProperty scope="context" name="plumelog.redisPort" source="plumelog.redisPort"/>
<springProperty scope="context" name="plumelog.redisAuth" source="plumelog.redisAuth"/>
<springProperty scope="context" name="plumelog.redisDb" source="plumelog.redisDb"/>
<springProperty scope="context" name="plumelog.env" source="spring.profiles.active"/>
<!-- 输出plumelog -->
<appender name="plumelog" class="com.plumelog.logback.appender.RedisAppender">
<appName>${plumelog.appName}</appName>
<redisHost>${plumelog.redisHost}</redisHost>
<redisAuth>${plumelog.redisAuth}</redisAuth>
<redisDb>${plumelog.redisDb}</redisDb>
<env>${plumelog.env}</env>
</appender>
<!-- 配置日志输出,只输出info,只保留控制台和plumelog输出-->
<!-- 正常开发环境本地,只输出到控制台,测试环境只输出到plumelog,生产环境输出到本地文件plumelog,因为有plumelog加持本地文件就保留3天即可-->
<!-- 这些都可以根据环境配置不同加载不同的ref->
<root level="info">
<!--输出到控制台-->
<appender-ref ref="CONSOLE"/>
<!-- 输出到文件 -->
<appender-ref ref="file"/>
<!-- 输出plumelog -->
<appender-ref ref="plumelog"/>
</root>
</configuration>
- 结合环境配置案例
<springProfile name="dev">
<root level="INFO">
<appender-ref ref="CONSOLE" />
</root>
</springProfile>
<springProfile name="test">
<root level="INFO">
<appender-ref ref="FILE" />
</root>
</springProfile>
<springProfile name="prod">
<root level="INFO">
<appender-ref ref="FILE" />
</root>
</springProfile>
-
小提示:为什么Spring Boot推荐使用logback-spring.xml来替代logback.xml来配置logback日志的问题分析
即,logback.xml加载早于application.properties,所以如果你在logback.xml使用了变量时,而恰好这个变量是写在application.properties时,那么就会获取不到,只要改成logback-spring.xml就可以解决。
这就是为什么有些人用了nacos等配置中心,不能加载远程配置的原因,是因为加载优先级的问题
4.log4j2 #
- 引入
<dependency>
<groupId>com.plumelog</groupId>
<artifactId>plumelog-log4j2</artifactId>
<version>3.5.2</version>
</dependency>
- 配置,示例如下:
<appenders>
<!-- 使用kafka启用下面配置 -->
<KafkaAppender name="kafkaAppender" appName="plumelog"
kafkaHosts="172.16.247.143:9092,172.16.247.60:9092,172.16.247.64:9092">
</KafkaAppender>
<!--使用redis启用下面配置-->
<RedisAppender name="redisAppender" appName="plumelog" redisHost="172.16.249.72:6379" redisAuth="123456">
</RedisAppender>
<!--使用lite启用下面配置-->
<LiteAppender name="liteAppender" appName="plumelog" plumelogHost="localhost:8891">
</LiteAppender>
</appenders>
<loggers>
<root level="INFO">
<!--使用上面三个三选一加入到root下面-->
<appender-ref ref="redisAppender"/>
</root>
</loggers>
(2)客户端配置详解 #
RedisAppender
| 字段值 | 用途 |
|---|---|
| appName | 自定义应用名称 |
| redisHost | redis地址,哨兵模式多个用逗号隔开 |
| redisAuth | redis密码 |
| redisDb | redis db 如果要切换db,redis必须要配置密码 |
| model | sentinel 哨兵模式,standalone 单机模式 |
| masterName | 哨兵模式需要配置哨兵的masterName |
| runModel | 1表示最高性能模式,2表示低性能模式 但是2可以获取更多信息 不配置默认为1 |
| maxCount | (3.1)批量提交日志数量,默认100 |
| logQueueSize | (3.1.2)缓冲队列数量大小,默认10000,太小可能丢日志,太大容易内存溢出,根据实际情况,如果项目内存足够可以设置到100000+ |
| compressor | (3.4)是否开启日志压缩,默认false |
| env | (3.5)环境 默认是default |
KafkaAppender
| 字段值 | 用途 |
|---|---|
| appName | 自定义应用名称 |
| kafkaHosts | kafka集群地址,用逗号隔开 |
| runModel | 1表示最高性能模式,2表示低性能模式 但是2可以获取更多信息 不配置默认为1 |
| maxCount | 批量提交日志数量,默认100 |
| logQueueSize | (3.1.2)缓冲队列数量大小,默认10000,太小可能丢日志,太大容易内存溢出,根据实际情况,如果项目内存足够可以设置到100000+ |
| compressor | (3.4)压缩方式配置,默认false(true:开启lz4压缩) |
| env | (3.5)环境 默认是default |
LiteAppender
| 字段值 | 用途 |
|---|---|
| appName | 自定义应用名称 |
| runModel | 1表示最高性能模式,2表示低性能模式 但是2可以获取更多信息 不配置默认为1 |
| maxCount | (3.1)批量提交日志数量,默认100 |
| logQueueSize | (3.1.2)缓冲队列数量大小,默认10000,太小可能丢日志,太大容易内存溢出,根据实际情况,如果项目内存足够可以设置到100000+ |
| env | (3.5)环境 默认是default |
| plumelogHost | 3.5 lite模式下plumelogserver的地址 |
| keepDay | 3.5 plumelog-lite 日志本地保留天数 |
(3)traceID生成配置 #
-
非springboot,cloud
-
方法一:添加拦截器
TraceIdInterceptorsConfig.java
import com.plumelog.core.PlumeLogTraceIdInterceptor;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.InterceptorRegistry;
import org.springframework.web.servlet.config.annotation.ResourceHandlerRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurerAdapter;
@Configuration
public class TraceIdInterceptorsConfig extends WebMvcConfigurerAdapter {
private static final String[] CLASSPATH_RESOURCE_LOCATIONS = {"classpath:/META-INF/resources/", "classpath:/resources/", "classpath:/static/", "classpath:/public/"};
@Override
public void addResourceHandlers(ResourceHandlerRegistry registry) {
//plumelog-lite的用户注意,拦截器会覆盖静态文件访问路径,导致不能访问查询页面,所以这边需要用addResourceLocations设置下静态文件访问路径,其他的用户可以不用管
registry.addResourceHandler("/**").addResourceLocations(CLASSPATH_RESOURCE_LOCATIONS);
}
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new PlumeLogTraceIdInterceptor());
super.addInterceptors(registry);
}
}
- 方法二:添加过滤器filter,新建一个过滤器
PlumeLogilterConfig.java
import com.plumelog.core.TraceIdFilter;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.servlet.Filter;
@Configuration
public class PlumeLogilterConfig {
@Bean
public FilterRegistrationBean filterRegistrationBean1() {
FilterRegistrationBean filterRegistrationBean = new FilterRegistrationBean();
filterRegistrationBean.setFilter(initCustomFilter());
filterRegistrationBean.addUrlPatterns("/*");
filterRegistrationBean.setOrder(Integer.MIN_VALUE);
return filterRegistrationBean;
}
@Bean
public Filter initCustomFilter() {
return new TraceIdFilter();
}
}
- webflux,以此类推
@Bean
public WebFluxTraceIdFilter initCustomFilter(){
return new WebFluxTraceIdFilter();
}
- servlet web.xml配置示例
<filter>
<filter-name>TraceIdFilter</filter-name>
<filter-class>com.plumelog.core.TraceIdFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>TraceIdFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
- spring boot,spring cloud 项目引入sleuth,项目之间采用feign调用的话,可以自己实现跨服务传递traceId
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
<version>2.2.7.RELEASE</version>
</dependency>
-
skywalking traceid获取方式
1.引入依赖jar包
<dependency>
<groupId>org.apache.skywalking</groupId>
<artifactId>apm-toolkit-trace</artifactId>
<version>6.5.0</version>
</dependency>
2.skywalking整合方法调用示例
import org.apache.skywalking.apm.toolkit.trace.TraceContext;
@Component
public class Interceptor extends HandlerInterceptorAdapter {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
String traceId = TraceContext.traceId();//核心是此处获取skywalking的traceId
TraceId.logTraceID.set(traceId);
return true;
}
}
- 定时任务,非web项目,在代码的执行最开始端加上如下代码
TraceId.set();
(4)开启链路追踪 #
-
这边注意:先要完成上一步,页面有了traceId(追踪码),这一步配置开启链路追踪才行,否则配置了也查询不了
-
链路追踪使用点我 《==要想产生链路信息请看这边文档,否则没有链路信息展示
(5)扩展字段功能 #
- MDC用法,例如,详细用法参照plumelog使用指南
MDC.put("orderid","1");
MDC.put("userid","4");
logger.info("扩展字段");
1.在系统扩展字段里添加扩展字段,字段值为 orderid 显示值为 订单编号
2.查询的时候选择应用名,下面会显示扩展字段,可以通过扩展字段查询
(6)错误报警说明 #
在ui的报警管理里配置报警规则:
字段说明:
| 字段值 | 用途 |
|---|---|
| 应用名称 | 需要错误报警的应用名称(appName) |
| 模块名称 | 需要错误报警的className |
| 接收人 | 填手机号码,所有人填写ALL |
| 平台 | 企微,钉钉,飞书,其他 其他表示自定义webhook |
| 钩子地址 | 群机器人webhook地址,或者自定义webhhok地址 |
| 错误数量 | 错误累计超过多少条报警 |
| 时间间隔 | 错误在多少秒内累计到上面错误数量开始报警 |
1.报警记录里为报警历史记录,点击可以直接连接到错误内容
2.请求webhook会带message(报警内容)和mobile(接收人手机号)两个参数,例如:http://你的webhook地址?message=报警内容&mobile=接收人手机号
(7)TraceId跨线程传递 #
如果不使用线程池,不用特殊处理,如果使用线程池,有两种使用方式,(plumelog-demo也有)
- 修饰线程池
private static ExecutorService executorService=TtlExecutors.getTtlExecutorService(
new ThreadPoolExecutor(8,8,0L,TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>()));
//省去每次Runnable和Callable传入线程池时的修饰,这个逻辑可以在线程池中完成
executorService.execute(()->{
logger.info("子线程日志展示");
});
- 修饰Runnable和Callable
private static ThreadPoolExecutor threadPoolExecutor=ThreadPoolUtil.getPool(4,8,5000);
threadPoolExecutor.execute(TtlRunnable.get(()->{
TraceId.logTraceID.get();
logger.info("tankSay =》我是子线程的日志!{}",TraceId.logTraceID.get());
}));
(8)滚动日志 #
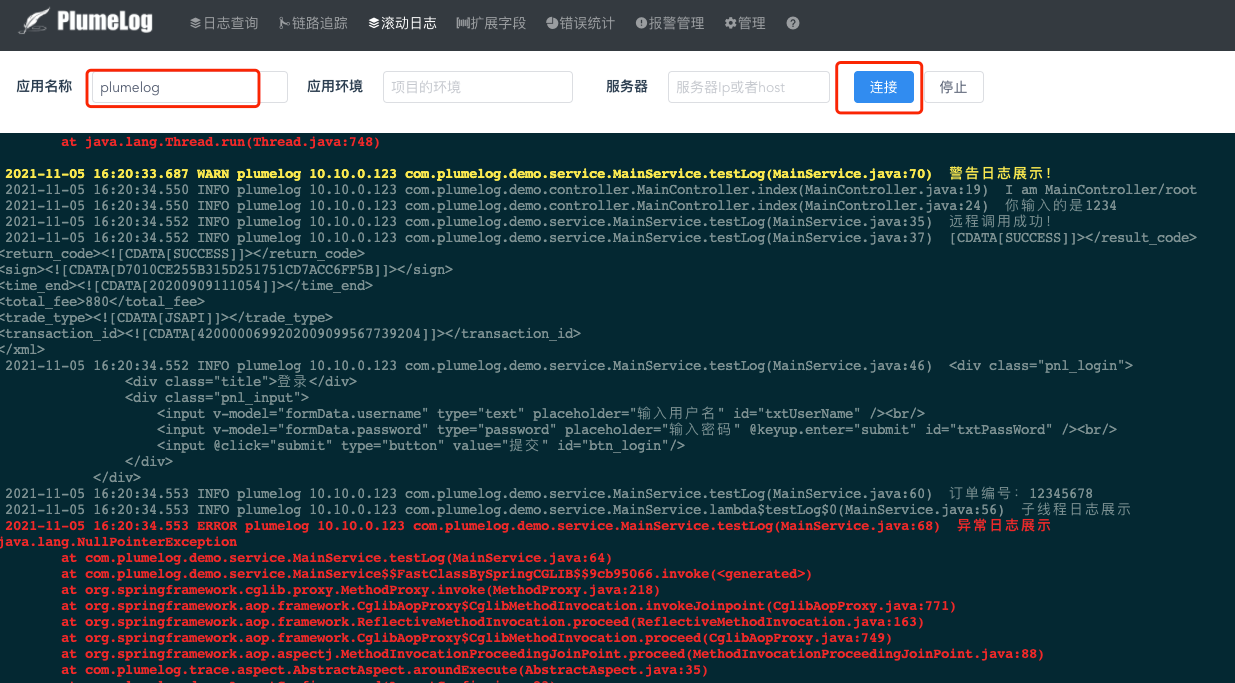
- 3.5版本支持查看滚动实时日志功能,点击滚动日志菜单,填入条件后,点击连接按钮,就可以实时滚动查看目标日志,三个查询条件,应用名称必填,否则没有日志输出
- 注意:因为实现原理问题,在查看滚动日志的时候肯定会影响server的性能的,用了nginx等做了反向代理的需要配置Nginx允许websocket
(9)springboot项目动态修改日志级别 #
-
3.5版本内嵌了springboot-admin,可以当springboot-admin使用,接入只要在项目的配置文件中加入
-
pom.xml加入
<dependency>
<groupId>de.codecentric</groupId>
<artifactId>spring-boot-admin-starter-client</artifactId>
<version>2.1.6</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
- application.properties 加入
#plumelog的地址加后缀admin
spring.boot.admin.client.url=http://localhost:8891/admin
management.endpoints.web.exposure.include=*
- 使用在plumelog地址后缀改成http://localhost:8891/admin 即可访问
(10)检查方法 #
-
第一步:先不用启动plumelog-server,先启动你的项目,用redis客户端连接到redis查看,plume_log_list这个key是否有数据,如果有说明你的项目到redis是通的,如果没有数据,说明项目配置有问题
-
第二步:上一步检查通过后,启动plumelog-server,继续观察plume_log_list这个key,如果数据没了,说明被消费了,说明下面这个链路是通了,如果没有,检查plume_log_list的plumelog.queue.redis的相关配置
-
第三步: 上一步启动完成后,打开后台界面:http://localhost:8891 查看是否有数据,如果有说明整个plumelog安装配置成功,如果没有,大概率是ES安装的有问题,查看plumelog的运行日志看看哪里报错了,或者用三方工具往ES里写数据看看有没有问题
-
遇到问题可以查看,下面第八章节,常见问题,后台查询语法详见plumelog使用指南
三、docker安装 #
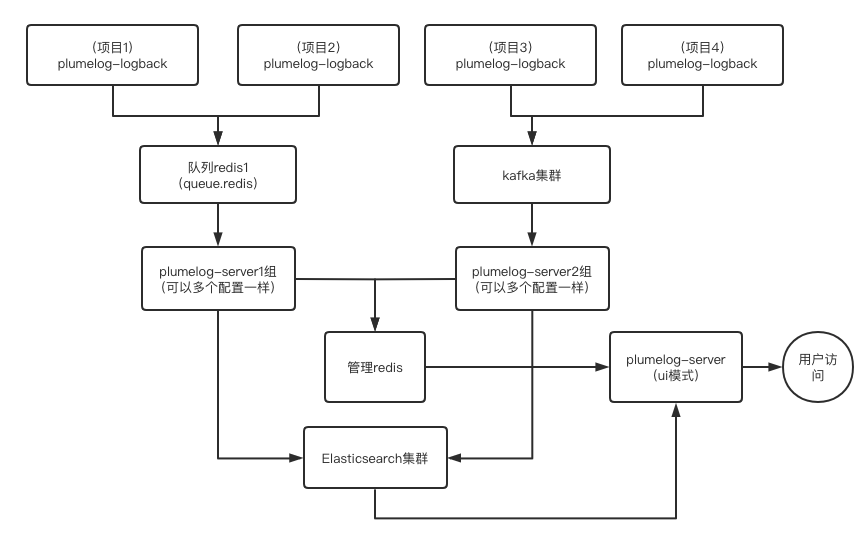
四、几种常见的部署模型 #
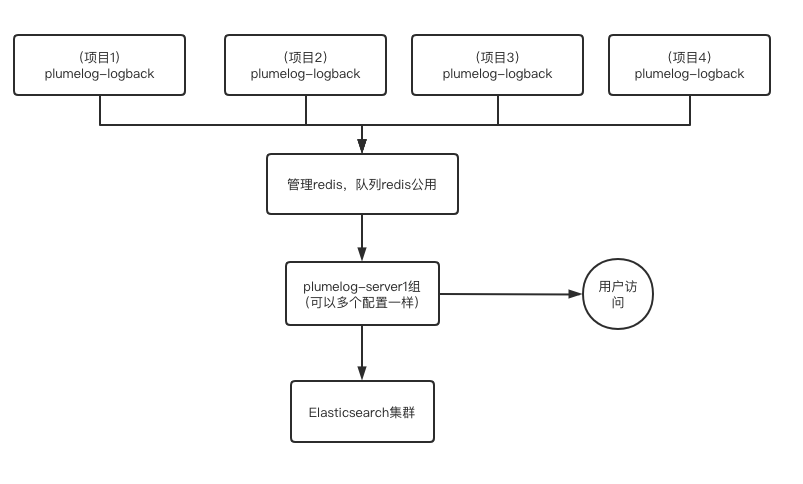
- 单redis小集群模式,大部分中小规模项目
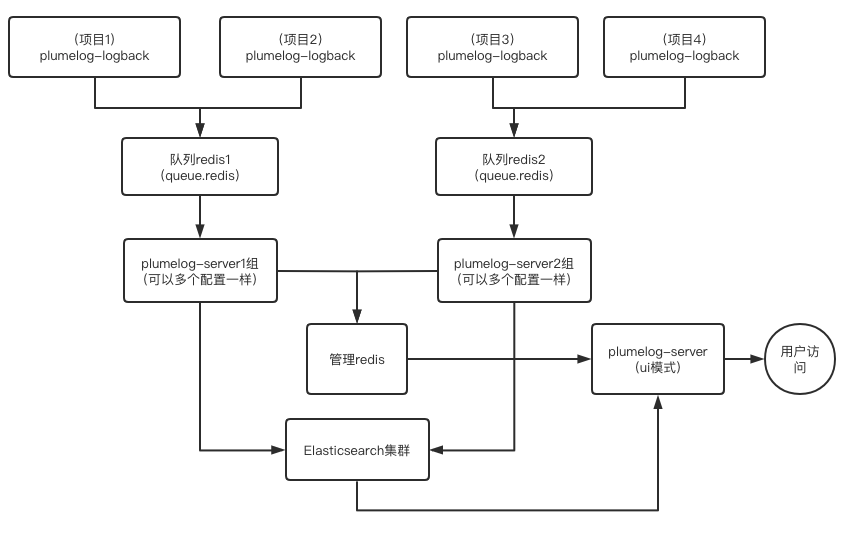
- 多redis大型集群模式,如果你的项目量大而且个别服务量特别大,建议用此方案
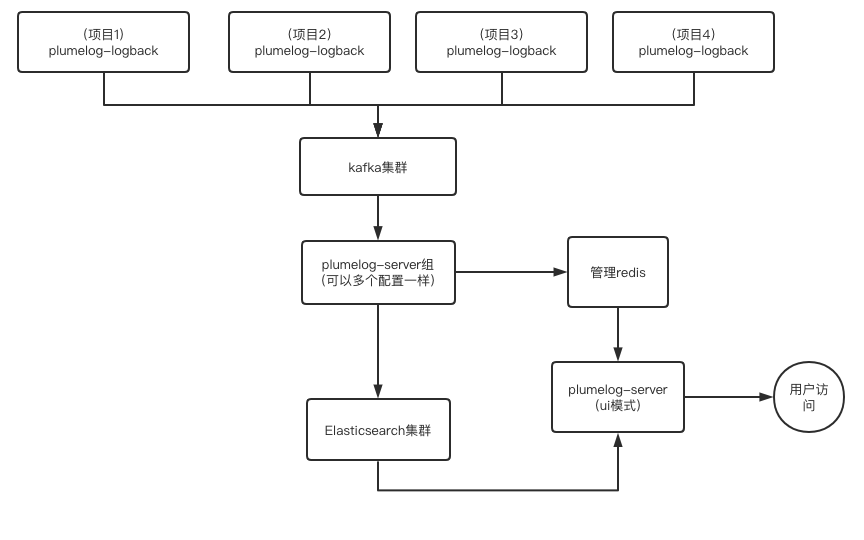
- kafka集群模式,每个项目量都很大
- redis和kafka混合部署模式,每个项目量都很大,有个别服务量更大
五、非java项目 #
可以api方式接入,3.2后版本server支持,暂时只支持redis模式
接口地址:http://plumelog-server地址/sendLog?logKey=plume_log_list
参数:body json数组,可以传多条可以单条
[
{
"appName":"应用名称",
"serverName":"服务器IP地址",
"dtTime":"时间戳的时间格式",
"traceId":"自己生成的traceid",
"content":"日志内容",
"logLevel":"日志等级 INFO ERROR WARN ERROR大写",
"className":"产生日志的类名",
"method":"产生日志的方法",
"logType":"1",
"dateTime":"2020-12-25 10:10:10"
},{
"appName":"应用名称",
"serverName":"服务器IP地址",
"dtTime":"时间戳的时间格式",
"traceId":"自己生成的traceid",
"content":"日志内容",
"logLevel":"日志等级 INFO ERROR WARN ERROR大写",
"className":"产生日志的类名",
"method":"产生日志的方法",
"logType":"1",
"dateTime":"2020-12-25 10:10:10"
}....
]
六、nginx日志搜集解决方案参考 #
七、自己编译安装如下 #
-
前提:kafka或者redis 和 elasticsearch 自行安装完毕,版本兼容已经做了,理论不用考虑ES版本
-
打包
-
maven deploy -DskipTests 上传包到自己的私服
私服地址到plumelog/pom.xml改
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<distribution.repository.url>http://172.16.249.94:4000</distribution.repository.url>
</properties>
-
非maven项目,到发行版中(https://gitee.com/frankchenlong/plumelog/releases )下载lib.zip,解压放到自己的lib目录,目前只上传了log4j的版本 可能会涉及log4j jar冲突,需要自行排除
-
jdk1.6的项目下载源码,编译打包plumelog-client-jdk6,引入到自己的项目
八、常见问题解答 #
-
redis在项目中充当什么角色?
redis在项目中两个角色,第一是在redis模式下充当消息队列,第二是项目本身的元数据存储和报警管理
-
为什么我查看redis中有数据,但是后台却查不到呢?
这种情况大概率是server中 plumelog.queue.redis.redisHost 没有配置正确,redis只是充当队列的作用,如果里面能看到数据说明没有server没有消费,正常情况应该是redis是不会积压的
-
为什么我配置了,之后后台无法查到日志?
排查方法:第一步:停止server,启动日志采集项目,观察redis中有没有数据,如果有说明从项目进入队列是通的,如果没有检查项目端redis配置是否正确;第二步:如果在redis有数据情况,启动server,如果server日志里有ElasticSearch commit! success;表示链路成功
很多小伙伴,配置了客户端,但是logback.xml或者log4j2.xml压根没生效,所以这时候需要停止plumelog-server,把第一步到Redis调通,到Redis调通了,启动plumelog-server看到日志在被消费掉说明成功了
-
为什么我链路追踪里看不到数据?
链路追踪模块产生的日志量比较大,考虑到低需求玩家,默认不集成,需要单独配置,详细查看文档:链路追踪配置
如果配置下来还是没有链路数据,第一检查是否有traceID,第二你的AOP生效了吗?
-
plumelog客户端配置能结合配置文件中心使用吗?
肯定是可以的,plumelog配置是配置在三大日志框架的配置文件里面的,可以使用springProperty进行管理配置,具体怎么操作看每个项目自己的情况
-
plumelog目前生产环境已知的已经有多大体量
根据用户反馈,目前搜集到最大的用户每日日志量已经到达3TB,并稳定运行
-
为什么我的项目继承了plumelog就启动就报错?
如果提示redis连接失败,那么说明redis配置错误,如果是其他错误,比如提示类找不到什么情况,应该数据日志配置文件错了,建议先熟练掌握log4j,logback配制文件里面的标签含义
-
plumelog会影响原来的日志配置么?
不会,plumelog只是增加了一种输出,不影响原来的配置
-
plumelog会影响项目性能么?
几乎不会,plumelog-lite在查询的时候可能会,必定是内嵌的
-
应用名称下拉框展开无数据?怎么回事?
下拉框展开为了保证性能,只有也没首次加载的时候会加载,当天如果有日志但是就是展开没有值可能是索引创建的时候出错了,怎么验证呢?
进入管理页面,点开运行数据表格中当天日志前面的箭头展开,如果里面有数据,说明索引没问题,此时只要关闭浏览器重新进入即可
如果展开什么都没有说明索引创建的时候分组信息丢失,选中点击重置索引,关闭浏览器重新进入即可
-
为啥使用统一配置中心nacos之类的,不能加载参数?
Spring Boot推荐使用logback-spring.xml来替代logback.xml来配置logback日志的问题分析
即,logback.xml加载早于application.properties,所以如果你在logback.xml使用了变量时,而恰好这个变量是写在application.properties时,那么就会获取不到,只要改成logback-spring.xml就可以解决。
这就是为什么有些人用了nacos等配置中心,不能加载远程配置的原因,是因为加载优先级的问题
-
plumelog挂了日志丢失怎么办?
plumelog的设计定位就是日志查询工具类系统,不可能去为了日志高幂等性去牺牲性能,甚至影响客户端,所以如果你担心plumelog挂了查不到日志,那你可以在本地再配置一个滚动日志保留三天作为补充